本文是针对x86-64指令和ABI的综述,其内容翻译自参考文献[1]。
1 引言
x86-64指令一般有两个操作数:源操作数和目的操作数,目的操作数也即指令执行结果。
linux下的x86-64指令格式采用AT&T格式,也即源操作数在左边,目的操作数在右边。
绝大多数x86-64指令采用后缀字母标示操作数的大小,例如q表示64为,b表示8位,w表示16位,l表示32位。
2 寄存器
x86-64有16个64位通用寄存器,在AT&T格式中使用%做前缀,其定义和在ABI中的角色如下表所示:
| Register |
Callee Save |
Description |
| %rax |
no |
result register, also used in idiv and imul |
| %rbx |
yes |
miscellaneous register |
| %rcx |
no |
fourth argument register |
| %rdx |
no |
third argument register, also idiv and imul |
| %rsp |
no |
stack pointer |
| %rbp |
yes |
frame pointer |
| %rsi |
no |
second argument register |
| %rdi |
no |
first argument register |
| %r8 |
no |
fifth argument register |
| %r9 |
no |
sixth argument register |
| %r10 |
no |
miscellaneous register |
| %r11 |
no |
miscellaneous register |
| %r12~%15 |
yes |
miscellaneous registers |
寄存器%rbp,%rbx和%r12~%r15是callee-save的,也即由被调用函数保存。
3 函数调用约定
Mac OS X和Linux操作系统的函数调用都遵从System V ABI,
有三个x86-64指令用来实现函数调用和返回:
call:返回地址(当前下一条指令地址)压栈,控制权转移到操作数所在的地址;
leave:设置栈指针%rsp为为帧%rbp,恢复帧指针%rbp为栈上保存的帧指针,
该指针从函数栈上弹出;
ret:返回值从函数栈弹出,并跳转到该地址;
3.1 函数参数
函数调用的前6个参数通过寄存器传递,传递顺序为%rdi,%rsi,%rdx,%rcx,%r8,%r9。超出部分的参数通过函数
栈帧传递。%rax用作第一个函数返回值,%rdx用作第二个函数返回值。
3.2 函数栈帧
函数栈帧从高地址往低地址方向增长,System V ABI使用两个寄存器访问函数栈帧:帧指针%rbp和栈指针%rsp。
帧指针%rbp指向当前函数栈帧基址(栈底),栈指针%rsp指向当前函数栈帧栈顶。
一般说来,帧指针%rbp用来存取函数栈帧上的数据,例如传递进来的函数参数,或者函数的本地局部变量。
System V ABI要求要求函数栈帧16字节对齐,这要求函数栈帧的大小应该是16的倍数。
函数栈帧结构图如下所示:
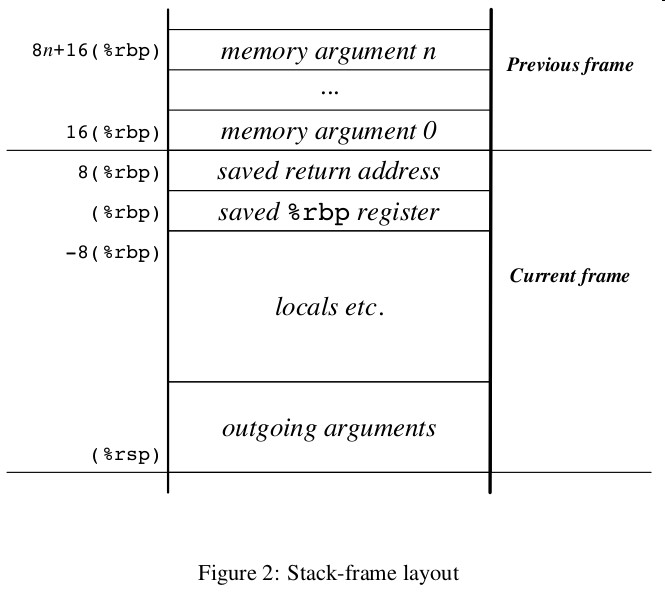
3.3 函数调用协议
函数调用协议分为caller端和callee端,每端各有两个重要步骤:
1)caller端首先保存caller-save寄存器到到函数栈上,并根据ABI加载函数参数到规定的寄存器和函数栈位置,然后执行call指令;
2)call指令使得程序控制转向callee函数,该函数首先需要执行链接和初始化任务,这些任务由以下指令序列完成:
pushq %rbp;
movq %rsp, %rbp;
subq $N, %rbp;
pushq指令用来保存帧指针,movq指令初始化帧指针为当前栈指针,subq指令为callee函数分配栈空间;对于callee-save的那些寄存器,如果在函数体中用到这些寄存器,那么接下来需要通过一系列pushq指令保存这些callee-save寄存器到函数栈帧上。程序接下来执行函数体部分代码。
3)函数体部分执行完以后,将执行callee返回部分:首先将函数返回值置入%rax中;然后释放函数栈帧空间,并恢复%rsp,%rbp寄存器;最后调用leave/ret指令返回到caller部分。
4)在caller端,如果它为callee的函数参数分配了存储空间,则在此时需要释放这些空间。
至此,一个完整的函数调用过程完成。
4 指令
关于指令部分,内容实在太多,具体请参考x86-64的指令手册。此处仅仅略述操作数。
x86-64指令的操作数有三种:寄存器(以%为前缀),立即数(以$为前缀)和内存地址。内存地址的寻址方式概述如下:
| Syntax |
Address |
Description |
| (reg) |
reg |
Base addressing |
| d(reg) |
reg+d |
Base plus displacement addressing |
| d(reg, s) |
s*reg+d |
Scaled index plus displacement, s in {2, 4, 8} |
| d(reg1, reg2, s) |
reg1+s*reg2+d |
Base plus scaled index plus displacement |
参考文献
http://www.classes.cs.uchicago.edu/archive/2009/spring/22620-1/docs/handout-03.pdf